
Data mining
- La metafora della miniera evoca lo scavare nel magma informe di dati per portare alla luce tesori di informazione e di conoscenza. Il data mining fa parte del processo di KDD e interviene dopo che i dati sono stati selezionati, processati e trasformati, per renderli il più possibile omogenei e funzionali allo scopo del progetto o delle decisioni da prendere.
Con l’uso di algoritmi appositi, reti neurali, clustering, alberi decisionali e analisi delle associazioni, i software di data mining esplorano i dati per far emergere somiglianze, diversità, ricorrenze che permettono di creare modelli che hanno questi compiti: - classificazione: individuare classi con determinate regole e raccogliervi gli elementi pertinenti (gli anziani);
- clusterizzazione: segmentare insiemi di dati con elementi omogenei, ma basati su regole scoperte durante l’analisi dei dati (anziani con tablet e anziani con e-reader);
- associazione: scoperta di nessi casuali ma ricorrenti come anomalie e particolarità (anziani che fanno jogging e pesca alla trota);
- regressione: gruppi ed elementi con variabili, ossia le regole di appartenenza a una classe, che possono assumere un numero elevato di valori, ed essere causali o indipendenti (gli anziani che pescano e leggono su e-reader sono per lo più laureati);
- serie storiche: regressioni complesse con variabili temporali (date, variazione dei tassi di interesse, ecc.), utili per fare previsioni (l’anziano che pesca e legge su e-reader potrebbe acquistare e-book di pesca e natura);
- scoperta di sequenze: associazioni per relazioni di dipendenza, causalità, conseguenza (l’anziano che pesca alla trota e legge su e-reader ha problemi di vista).
L’analisi dei dati può essere descrittiva (che cosa è successo), predittiva (che cosa potrebbe succedere), prescrittiva (che cosa dovrebbe succedere).
Un modello o pattern è il risultato dell’estrazione dei dati. Indica una struttura, una tipologia, un genere di relazione, una rappresentazione sintetica dei dati. Deve essere:
- comprensibile, l’utente deve poterlo interpretare da un punto di vista semantico e sintattico;
- utile, l’utente deve comprendere come lo può utilizzare;
- valido, affidabile per la qualità, la chiarezza e l’attendibilità dei dati;
- sconosciuto prima del data mining, altrimenti non aggiungerebbe valore.
Il data mining si usa nel marketing, in economia e finanza, statistica, scienze, ICT, gestione d’impresa.
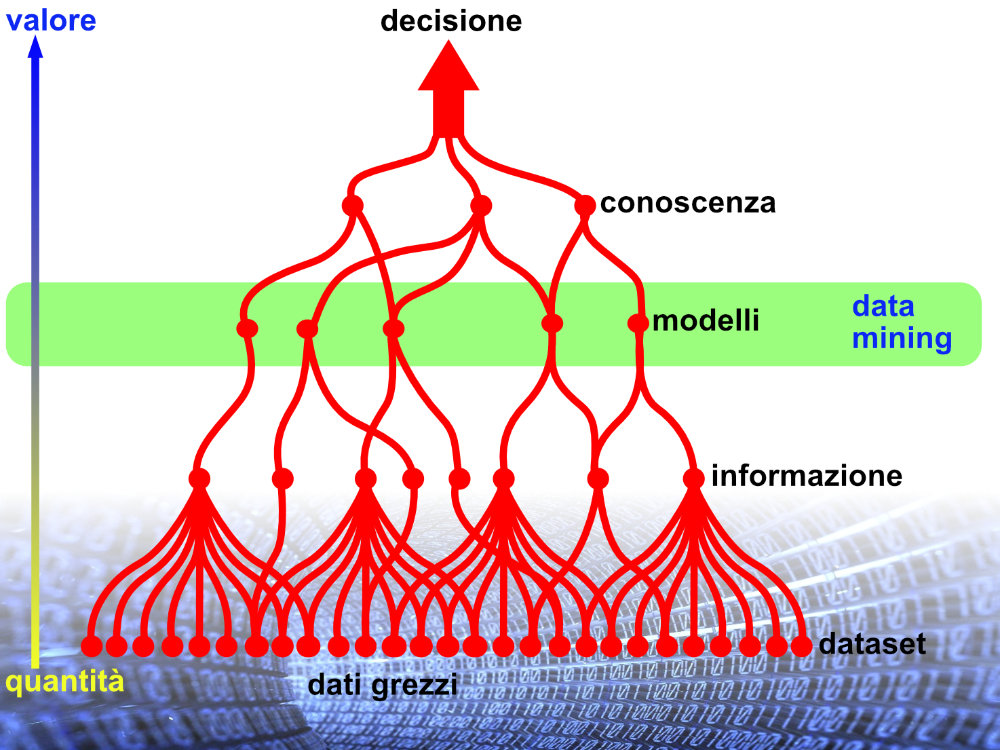
Il data mining è qualcosa di più e di diverso rispetto alla ricerca di informazioni, come cercare un numero telefonico sulle pagine bianche, perché i dati raccolti e selezionati sono analizzati semanticamente, combinati e visualizzati in funzione del problema da risolvere. Dai dati grezzi, dopo aver circoscritto il dataset, si estraggono e si processano le informazioni, si evidenziano i modelli, si arriva alla conoscenza che permette di prendere decisioni.
Il data mining ha fatto enormi progressi con l’impiego dell’intelligenza artificiale, perché i sistemi di deep learning imparano lavorando, e quindi diventano sempre più efficienti. Più è alto il numero di dati processati, più e meglio si possono estrarre modelli ricorrenti e relazioni complesse impossibili da comprendere per una mente umana.
