
Sistema di raccomandazione
Prima di Internet, o nei primi anni di diffusione della rete delle reti, cercare informazioni utili ad un progetto era molto difficile e richiedeva ricerche lunghe, faticose e spesso costose, quando si dovevano acquistare libri o spostarsi per fare interviste o consultare biblioteche. Oggi motori di ricerca come Google forniscono immediatamente migliaia o milioni di risposte alle nostre domande. L’abbondanza di informazioni però spaventa: se qualche anno fa era facile leggere una decina di pagine di risultati di una ricerca, oggi, di fronte a 10 milioni di risultati, ci demoralizziamo, non leggiamo nulla e smettiamo di cercare. Da questo problema nascono i primi sistemi di raccomandazione, software integrati in portali web, strumenti di sviluppo che aiutano l’utente ad ottenere solo le risorse più pertinenti alle sue esigenze, e lo orientano nello scegliere che cosa leggere, che cosa acquistare, dove andare, con chi mettersi in contatto.
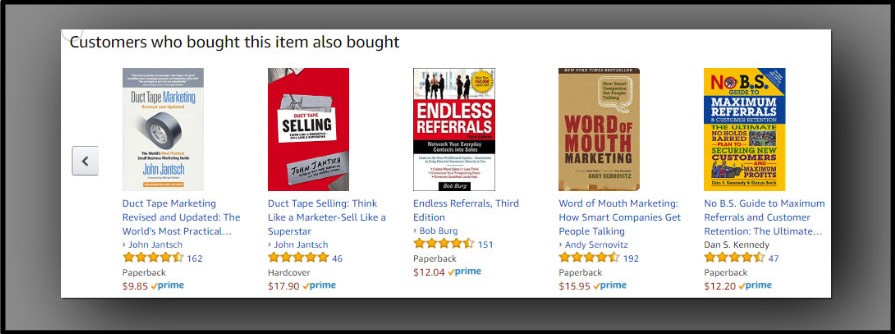
A tutti noi è capitato, consultando Amazon o cercando un programma su Netflix, di veder apparire, accanto al libro o al film che ci interessa, suggerimenti di altri libri e altri film o serie tv. Netflix dice: “Dato che hai visto House of Cards ti potrebbe piacere…” e mostra le copertine di un certo numero di prodotti simili. Amazon dice: “I lettori di questo libro gradiscono anche…” e seguono altri tre o quattro libri. Lo stesso avviene nei portali di e-commerce come Pixmania o E-Bay che dicono: “in genere questo prodotto è acquistato insieme con…” e mostrano due o tre accessori. Questi sono gli effetti dei sistemi di raccomandazione, vantaggiosi sia per chi offre un servizio o vende un prodotto, sia per l’utente del servizio o l’acquirente del prodotto, che si incontrano con più frequenza, più facilità e più precisione. Amazon ha usato un approccio content based, gli altri tre un approccio collaborative filtering.
Un sistema di raccomandazione si basa su:
- items: gli oggetti da raccomandare;
- users: gli utenti di quel sistema;
- transactions: le interazioni avvenute fra utenti e sistema;
- rating: le valutazioni date dagli utenti in termini di rapporto qualità/prezzo.
Il sistema, e quindi l’algoritmo che seleziona le informazioni pertinenti, può essere:
- content based: l’item è ritenuto utile in base a item simili già considerati dall’utente;
- collaborative filtering: la valutazione di un item tiene conto di valutazioni fatte da utenti simili;
- demographic: gli utenti sono suddivisi in categorie a cui si indirizzano le raccomandazioni;
- knowledge based: la raccomandazione è fatta entro un ambito specifico di conoscenze;
- community based: le raccomandazioni tengono conto delle preferenze degli amici dell’utente;
- hybrid: combinazione di due o più metodologie precedenti.
Quando si mette in moto un sistema di raccomandazione, per esempio appena fatto l’abbonamento a Netflix o con i primi acquisti su Amazon, il sistema deve affrontare i problemi di
- cold start: il sistema non ha informazioni sufficienti sui gusti del cliente che non ha ancora fatto abbastanza consultazioni e scelte;
- sparsity: i prodotti valutati dal cliente sono troppo pochi.
La raccomandazione quindi è tanto più accurata e pertinente per l’utente, quanto più l’utente ha frequentato il sistema, facendo ricerche, commentando, acquistando. Se i dati riguardanti l’utente sono troppo pochi, il sistema lo include in un gruppo di utenti che hanno profili simili, e prova a fargli le raccomandazioni fatte a quel gruppo, per poi aggiustare il tiro in base alle interazioni dell’utente. Ne deriva che più siamo intelligenti nelle nostre richieste, più riceveremo raccomandazioni intelligenti e pertinenti. Più siamo sciatti, più saremo vittime di raccomandazioni che ci impongono gusti altrui.
